![A Comprehensive Guide to Document Classification [Challenges, Methods & Benefits]](https://blog.arya.ai/content/images/size/w960/2024/02/A-Comprehensive-Guide-to-Document-Classification.png)
Data is crucial for any organization or business, especially for banks and financial organizations. Financial institutions collect and store a lot of customer data in their database—and it’s of greater use only when interpreted and organised properly.
From loan applications and P&L statements to bank statements, financial organizations need to handle a plethora of documents, which consist of valuable insights and sensitive data essential for decision-making and operational efficiency.
According to the Data Analytics in Banking Market Report by Allied Market Research, the global data analytics market will increase at a CAGR of 19.4%, from $4.93 billion in 2021 to $28.11 billion in 2031. This shows the growing importance of AI in the banking sector regarding data analysis and reporting.
While manual document classification is possible, it’s highly time-consuming and increases the chances of human errors and inconsistencies. This is where automated document classification comes into play—providing a time-efficient and effortless solution to classify and organize documents.
In this blog, we dive deep into document classification, methods of document classification, challenges, and more.
Document classification organizes documents into different categories based on their characteristics and content to simplify accessibility.
This can be done manually, or the entire process can also be automated.
The process of document classification is highly beneficial for banks and financial institutions. Here are a few benefits of document classification for banks:
Documents are a combination of text and images. Based on this nature, we can classify them into two categories:
Let’s understand each of these categories in detail:
As you might have already guessed from the name, text classification involves extracting and analyzing the document's textual content. The textual content can be a sentence, paragraph, word, or phrase. There is less context to work with, this classification type is considered more complex than others. It works well for text-heavy documents like emails, reports, and articles.
The image-based classification method only focuses on analyzing the visual content of documents. It allows you to gain valuable insights from visual data. This classification process is done for graphs, charts, tables, infographics, etc.
While document classification holds immense potential for organization, efficiency, and insight extraction, it's not without its challenges. You need to understand the hurdles in this process to tackle them easily.
Here are the most common challenges a business faces during document classification:
Documents come in all shapes and sizes, each with its unique format, language, and structure. The sheer diversity of data, from PDFs and spreadsheets to handwritten notes, poses a significant challenge.
Deciphering the meaning and context of heterogeneous data requires robust techniques for handling various formats and languages.
Not all documents are created equal. Some are straightforward and concise, while others are riddled with ambiguity and nuance. Understanding the true intent behind vague or poorly structured content presents a formidable challenge.
Missing information, typos, and inconsistencies within documents can be confusing, leading to inaccurate results. On top of that, specific document categories might be inherently subjective or ambiguous, making their classification challenging and prone to disagreements.
As the volume of documents grows exponentially, scalability emerges as a pressing concern for document classification systems. With manual processes, you cannot keep up with the sheer volume of data, inevitably leading to bottlenecks and inefficiencies.
Classification of documents is not only tedious but also consumes valuable time and resources. Sorting through documents, labeling them, and organizing them into categories can be incredibly time-consuming, diverting human resources away from more strategic tasks.
Different industries present unique challenges and nuances when it comes to document classification. Legal documents, for example, may contain complex language and terminology not commonly found in other domains. Similarly, medical records may include sensitive information and intricate medical terminology that require specialized handling.
To ensure accurate classification results, addressing domain-specific challenges requires tailored approaches and domain expertise.
To tackle these challenges, you will need a solution to support each part of the process and scale your business.
Intelligent Document Processing, or IDP, is the solution to this problem. IDP is a holistic approach to document management that leverages a suite of AI and ML technologies to automate and optimize document-centric workflows. This solution automates the entire categorizing process and improves the overall accuracy.
When you enter a document in an IDP system, it is automatically identified, classified, assembled, and processed according to its nature.
Take a look at the powerful technologies that power IDP:
Computer Vision Recognition: This AI-powered technology enables computers to “see” the visual content of documents such as images and videos. It helps you locate visuals by applying filtering and searching options.
Object Detection is another part of computer vision recognition. It usually applies to businesses dependent on a large-scale classification to operate smoothly. For example, object detection is highly useful for a logistics business, where scanning QR codes is part of daily operations.
Optical Character Recognition (OCR): OCR or Text Recognition is used to mine text from scanned documents and images to be converted into a machine-readable format. Typically, this technology is paired with AI and ML to achieve greater accuracy.
Rule-based Text Recognition: Rule-based text recognition relies on predefined rules to extract specific information from text documents. This approach allows users to establish rules based on patterns, keywords, or regular expressions and facilitates precise identification and extraction of relevant data elements.
Natural Language Processing (NLP): This technology analyzes the structure and meaning of text, which enables tasks like document summarization, topic classification, and even answering questions directly from the content. It provides deeper insights and understanding of textual documents. NLP can also delve into the semantic meaning of text. That means it can categorize documents according to content.
While implementing this technology, you can take either of two approaches:
Leveraging automation to classify documents can provide multiple benefits to banks and financial institutions:
Documents are supposed to serve as the cornerstone of trust and transactions. Yet, this reliance becomes a vulnerability exploited by a growing threat: document fraud. Forged invoices, fake identities, and misrepresented data, the scale and sophistication of these scams are escalating, impacting individuals, businesses, and entire economies.
According to a report by the Association of Certified Fraud Examiners, companies lose 5% of their revenue annually to occupation fraud.
Beyond the immediate financial losses resulting from fraudulent transactions or contracts, document fraud undermines trust and credibility, tarnishing the reputation of businesses and eroding customer confidence.
Document fraud not only affects businesses but also directly threatens individuals' privacy and security. Identity theft, one of the most common forms of document fraud, can wreak havoc on victims' lives, leading to financial ruin, damaged credit, and emotional distress.
Technological advancements like deepfakes and AI-powered forgery tools empower fraudsters with new capabilities, making it increasingly difficult to discern what is real from what is fake.

While the rise of AI can be blamed as one of the factors enabling fraudsters to commit this serious crime, in the right hands, it can also be the solution to combat this threat.
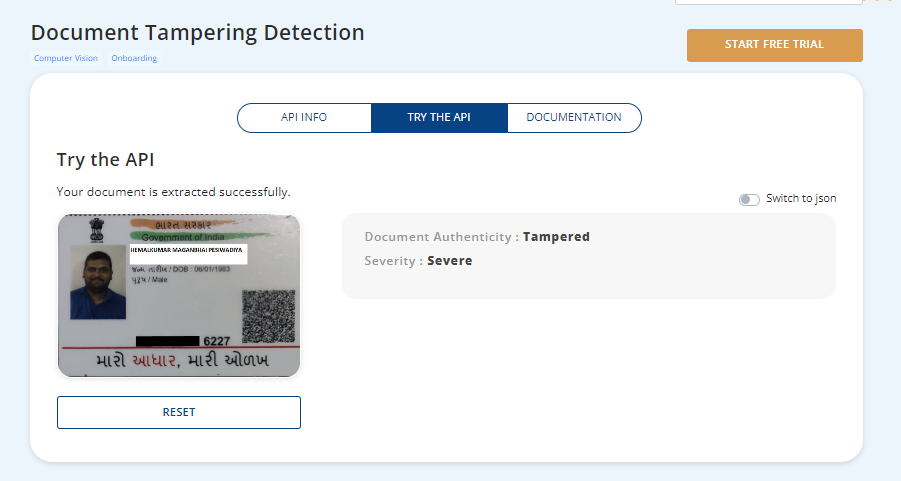
Here is how AI can assist you with Document Tampering Detection:
AI algorithms scrutinize every aspect of an image, such as pixel-level comparisons, texture analysis, object-lighting consistency, and much more. Along with this, AI, paired with deep learning architectures like convolutional neural networks (CNN), can meticulously analyze the visual content of documents, identifying anomalies and alterations that may indicate tampering.
Document tampering often leaves behind telltale patterns and artifacts that betray its deceitful nature. AI excels at pattern recognition, discerning subtle deviations from the norm that indicate forgery.
Beyond the surface-level examination of visual content, AI delves into the hidden metadata embedded within digital documents. Metadata analysis allows AI systems to scrutinize timestamps, authorship information, and revision history to uncover discrepancies that can signal tampering attempts.
Document tampering often involves subtle alterations designed to evade detection by human observers. AI employs anomaly detection techniques to identify deviations from expected patterns or distributions within documents, flagging suspicious areas for further investigation.
Whether it's inconsistencies in font styles, discrepancies in alignment, or unexpected changes in content, AI's keen eye for anomalies is an indispensable tool to combat document tampering.
To help you combat document fraud, Arya AI has developed a curated API for Document Tampering Detection. It leverages cutting-edge deep learning techniques to:
Leverage Arya AI's Document Tampering Detection API to protect your business from being the victim of document fraud!
Curious to know more about how the API works? Dive into our blog for a closer look at its functionality and effectiveness.
We live in an era where every invoice, contract, and report holds invaluable insights and sensitive data.
Businesses must organize documents into relevant categories based on content and characteristics to improve accessibility, productivity, and decision-making prowess.
The need for an intelligent document management solution has never been more pressing. With AI-based classification systems, organizations can overcome manual processing challenges, achieve higher accuracy levels, and scale effortlessly to meet the demands of your growing business.
This transformative technology can also help you fortify your defenses against document frauds that can harm your business.